
The words of the ninth Democratic debate
- Sonia Ben Hedia

- Apr 10, 2020
- 10 min read
Lately, I have been playing around a bit with scraping data from the web and doing some fun linguistic analyses and visualizations with the data. Data from political debates form a wonderful opportunity to do these kinds of things. You have different speakers you can compare with regard to HOW MUCH they say and WHAT they say, and it might actually be really informative. So, a few weeks ago I started looking at the data from the ninth Democratic debate and I would now like to share my insights with you. The code I wrote to attain these insights, as well as all supporting material, can be found on my GitHub.
How I got the data
After finding the full transcript of the democratic debate online, I used the requests package to pull the HTML from the website. To pre-process the data, I created a BeautifulSoup object from the HTML (bs4 package). With the help of regular expressions (re-package) and by making use of the HTML structure, I then created a dictionary. The speakers of the debate served as keys, their utterances as values. In addition to this 'original' dictionary, I also created a dictionary that only contained content words (words with meaning), leaving out the so-called stop or filler words. Furthermore, I ensured that compounds, such as health care (a word that was quite frequent in the debate) was treated as one and not two words. The two dictionaries form the basis of all linguistic analyses conducted.
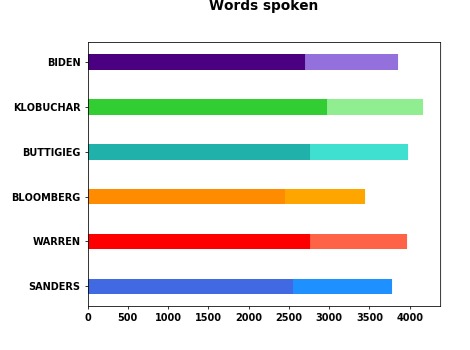
How much was said?
My first interest was to see how much every potential candidate contributed to the debate. Below you see a pie chart depicting the percentage of words each candidate produced in the debate (including stop words). Overall, it is pretty equally distributed among speakers with Amy Klobuchar speaking the most (18.3 % of all words spoken) and Michael Bloomberg speaking the least (15.1 % of all words spoken). Note that the difference of 3.2% between the two amounts to 520 words. Assuming that an average English sentence consists of 15 words, Klobuchar produced approximately 35 more sentences than Bloomberg. And assuming that an average person produces around 120 words per minute, Klobuchar spoke around 4.5 minutes more than Bloomberg.

Note that I computed the average English sentence length by dividing the number of words (tokens) in the spoken part of the contemporary Corpus of American English by the number of sentences in the corpus. The number of sentences was approximated as the sum of occurrences of dots, exclamation marks and question marks. The average speech rate in English was estimated based on the mean speech rate in the speech production studies of my dissertation.
How informative were each candidate's utterances ?
Now we know how much each candidate said, but the question of how much actual content the candidates conveyed remains. We all know someone who speaks a lot but does not really say much. So let's have a look at this issue!
There are several ways in which we can estimate the content value of speech. I opted for two rather simple but effective methods. First, I analyzed how many of the uttered words were content words and how many were filler words (also called stop words). The difference between the two is that content words have meaning and are thus very informative whereas filler words, such as the and of, do not hold lexical information and are thus not very informative. We can assume that someone who uses more content words conveys more informative content. However, we need to also keep in mind that stop words are a necessary part of language and that the ratio of content vs. stop words might be very similar between speakers.
Looking at the graph below we see the ratios of content vs. filler words for each speaker. As expected, they are pretty similar between the speakers, ranging between 40% for Bloomberg and Klobuchar to 48% for Sanders. Biden (43%), Warren (43%), and Buttigieg (44%) lay in between. If one needed to draw a conclusion from this, one would say that Bernie Sanders seems to convey the most meaning with the least words, and that Biden and Klobuchar used the most words conveying the least meaning. However, as I said before one must be careful to not overinterpret this result as all of the ratios are very similar.



The second 'content-measure' is the type-token-ratio. A type is a specific word, such as health insurance which may be repeated several times. In other words, there might be several tokens of the type health insurance in a given text. The type-token-ratio thus tells you how many repetitions are present. In our case, it tells us how many unique words a speaker used. The more unique words s/he used, the more likely it is that s/he conveyed more content (of course there is the possibility of using synonyms but I won't go into that). So, let's see what the candidates did in the debate.

On the right you see a graph depicting the type-token-ratio for each speaker. The ratios range between .48 for Amy Klobuchar, who repeated herself the least, and .55 for Joe Biden who repeated himself the most. Overall, one can say however that all candidates are in the same 'repetition realm'.
So, who conveyed the most information? The numbers suggest that while overall there is no big difference between the candidates, Sanders used the highest percentage of content words, Klobuchar and Buttigieg the least. Interestingly, Klobuchar repeated herself the least even though she did use the least percentage of content words. Biden is the candidate who used the most repetitions.
What did they talk about?

Now we know how much was said, and we have an idea about how informative the utterances of each candidate were. But what did the candidates talk about? An easy way to find out is by looking at frequencies, i.e. by asking which content words were used the most. On the right you see the ten most used words in the debate. In parentheses you see the number of occurrences of each word.
From a qualitative point of view, we can group these ten words into four groups. First, we have the words people and country, both denoting the addresses of the debate, i.e. the entities the candidates want to represent and the ones they want to convince. Second, we have the two words Donald Trump and president, both essentially referring to the same real-world entity. So, it seems that the current administration was discussed quite frequently in the debate. One should note, however, that the term president could of course also refer to the future president. In other words, the candidates have also used this term to refer to the actual position they are competing for (e.g. 'We could nominate a woman for candidate for president of the United States', Klobuchar). The third group is made of the words think, want, right and need. The frequent use of these words is not really surprising as it is a nature of a debate to express one's opinions and thoughts, especially with regard to what is right and what the country needs. The last, the fourth group is formed by the words healthcare and care. This is extremely interesting as it indicates that next to the current administration, the health care system forms the other mostly discussed topic in the debate.
After having looked at the frequent words for all candidates, let us now have a close look at each candidate individually. To do so, I created word clouds for each candidate using the word cloud package. For each candidate these word clouds represent his/her most frequently used words. The bigger the words are represented, the more often they were used by the candidate.












Let us look at each candidate's donkey individually (I thought the democratic donkey would be a fitting shape for the word clouds). Instead of discussing every frequent word in the candidates' donkeys, I will just point at some interesting patterns I see.
For Pete Buttigieg, the pattern I see is that he talks about what America needs now and that he wants to take action for a change. I base this on his use of words like people, American and president, as well as plan, now and need. Furthermore, his frequent use of the term think is interesting. Think is often used as a hedge, and it often weakens your statement. Just consider the two sentences: 'I think you have to accept some responsibility" (as Buttigieg said it in the debate) vs. 'You have to accept some responsibility '. The second sentence comes off much stronger, i.e. more convincing.
What strikes me about Elizabeth Warren's donkey is the frequent use of the words need and want. Together with the frequent use of the term people, this suggests to me that Warren talked very much about the people's perspective, i.e. tried to take a more empathetic approach. Furthermore, she seems to have talked about the current president as well as the healthcare issue quite a bit.
Joe Biden's donkey is quite different from Warren's as it suggests that he takes a more 'neutral' stance, talking about facts and numbers quite a bit (see the frequent words two, billion, number, facts). What also strikes me is that his language seems very proactive using active verbs like go, make and stop. Biden also seems to talk about the present president quite a bit, as well as about financing (frequent use of the term money).
Mike Bloomberg's donkey shows the words city and New York, suggesting that in his utterances he often referred to his former experiences. Also, the words money and job show up, suggesting that he mainly talked about economic topics. Bloomberg seems to have used words like will, let, got and think a lot. These words, even though they can be considered content words, do not seem very informative as they do not refer to a specific problem or aspect. The fact that Bloomberg used think a lot (see discussion of think above) might suggest that his utterances were not very convincing.
Amy Klobuchar's donkey, similar to Pete Buttigieg's and Mike Bloomberg's, is dominated by the word think. Thus, the discussion about hedging can also be applied to her speech. What also strikes me is the frequent use of the term heart. First I thought this might be related to the discussion of Bernie Sander's heart issues but then I looked into the data (something someone should always do!), and Klobuchar actually talks about the heart in sense of emotions and empathy, something which sets her apart from her competitors. Apart from the people's needs, she talks a lot about the current president, similar to most of the other candidates.
It does not seem surprising that Bernie Sanders' donkey is dominated by two topics, on the one hand health care on the other rich people, indicated by the frequent use of the words million, billionaires and Bloomberg. He furthermore talks about the industry and workers. Interestingly, he does not mention the current president to frequently but seems to rather concentrate on concrete topics. What strikes me is his frequent use of the words talk and maybe. Looking at his utterances, it seems like he uses these words as rhetoric devices to engage his interlocutor, such as in 'Maybe we can talk -- maybe we can talk about...". He also uses the term maybe quite frequently to suggest rather provocative ideas, such as in 'Maybe your workers played some role in that, as well.'. I might go out on a limb here, but I feel like this could be part of his debating strategy which I consider extremely interesting.
Summary
The numbers
The differences in the number of utterances for each candidate were rather small. This is not surprising as a good debate host will lead the debate in such a way that every participant gets his share of speaking time. With regard to how informative each candidate's utterances were, we can state that there are also only small differences between them. This also is not surprising as the structure of language limits the range of informativeness to a certain degree, i.e. not allowing for too large differences between the speech of the candidates. However, we can see some smaller differences and these I will summarize below for each candidate.
Joe Biden: With 16.6 % contributed moderately to the discussion. His use of content words is in the midfield (43%). He repeated himself the most (55%).
Mike Bloomberg: Spoke the least (15.1 %) and used the least content words (40%). His repetition rate is in the midfield (52%).
Pete Buttigieg: Spoke a lot (17.1 %), used an average rate of content words (44%) and repetitions (52%).
Amy Klobuchar: Spoke the most (18.3%), using the least content words (40%). She repeated herself the least (48%).
Bernie Sanders: Did not speak too much (15.8%) but used a high number of content words (48%). His repetition rate is in the midfield (51%)
Elizabeth Warren: Spoke a lot (17.1 %) and used an average rate of content words (43%) and repetitions (53%).
Content and more
Contentwise we can say that the main topic of the debate seems to have been the health care system. Also, the candidates frequently discussed president Donald Trump. Below I will summarize the topics which seem to have been the most prominent for each candidate. Furthermore, I'll summarize some interesting patterns in their word usage.
Joe Biden: Very fact-based and numbers-oriented approach and frequent use of proactive language. Talks about the economy and the current president.
Mike Bloomberg: Talked a lot about his previous experience and seems to be focused on the economy. Uses a lot of hedges, which might lead to unconvincing language.
Pete Buttigieg: Very change-driven but not very concrete with regard to content. High usage of hedges based on the frequent use of the word think.
Amy Klobuchar: Uses a lot of hedges, addresses emotional aspects (frequent use of heart), and talks about the current president.
Bernie Sanders: Health care and billionaires, interesting use of the word maybe to make controversial suggestions.
Elizabeth Warren: Very empathetic, also talking about the current president as well as health care issues.
Disclaimer
I know that politics is a sensitive topic, and this is why I feel the need to add a short disclaimer to this post. I tried to be very objective in my analysis and let the numbers and data speak. Of course, I interpreted the data and I am sure that I am biased in some way or the other. No matter how hard we try, we will always see things, in this case data, from a subjective point of view.
My methodology of mainly using statistical data analysis tools might also have lead to wrong conclusions. There are so many types of analyses one could have used. And some of these might have been a better choice to analyze the debate, e.g. discourse analysis. I chose to use a more quantitative type of approach, paired with some content analysis. The reason is that, as I said at the beginning of this post, this is just a fun small project I use to explore and expand my skills. So, what I want to say: Do not take this post or my implications too seriously. Just have fun exploring the data!
Comments